Building a Simple Document Assistant with Streamlit and OpenAI
This project showcases a simple document assistant built using Streamlit and OpenAI, specifically leveraging Retrieval-Augmented Generation (RAG).
Building a Simple Document Assistant with Streamlit and OpenAI
This project showcases a simple document assistant built using Streamlit and OpenAI, specifically leveraging Retrieval-Augmented Generation (RAG). This tool enhances the capabilities of Large Language Models (LLMs) by integrating them with external knowledge sources, enabling them to generate more accurate, informed, and contextually relevant responses from documents.
Problem Statement
Traditional purely generative LLMs can sometimes struggle with factual accuracy or providing information specific to a given document. This project addresses this by allowing the LLM to retrieve relevant information from a specified document before generating a response, thereby improving the quality and contextual relevance of the output.
Technical Approach
The document assistant employs a Retrieval-Augmented Generation (RAG) approach, combining the power of LLMs with efficient information retrieval.
1. Data Loading and Preparation
PyPDFLoader: Used for loading PDF files and converting their content into processable text.
RecursiveCharacterTextSplitter: Splits large texts into smaller, manageable chunks. This is crucial for efficient processing and to prevent memory overload when embedding and querying.
2. Vector Database Creation
The core of the retrieval mechanism lies in the vector database:
OpenAIEmbeddings: Converts document text chunks into high-dimensional vectors, capturing their semantic meaning.
Chroma: Stores these vectors, allowing for quick retrieval of relevant document sections based on cosine similarity to a user's query. This project uses Chroma for its ease of local management.
# Function to create a vector database from a PDF document
from langchain.document_loaders.pdf import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
import os
def create_vector_db():
embedding_function = OpenAIEmbeddings(api_key=os.environ['OPENAI_API_KEY'])
docs = PyPDFLoader('./MY_PDF_FILE.pdf') # Placeholder for actual PDF path
docs = docs.load_and_split(text_splitter=RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100))
db = Chroma.from_documents(docs, embedding_function)
return db
3. Interactive User Interface
Streamlit is an excellent choice for building a quick and intuitive chatbot interfaces due to several key advantages:
- Rapid Development: Streamlit's simple Python-based API allows for quick prototyping and development of interactive web applications without requiring extensive web development knowledge.
- Built-in Chat Components: The framework provides ready-to-use chat interface components (st.chat_input, st.chat_message) that handle message display and user interactions.
- Real-time Updates: Streamlit's streaming capabilities (st.write_stream) enable smooth, real-time display of AI responses, enhancing the user experience.
- Session State Management: Built-in session state handling makes it easy to maintain conversation context and user data.
- Python Integration: Seamless integration with Python-based AI and NLP libraries makes it ideal for implementing the backend logic of chatbots.
4. Query Processing and Response Generation
When a user submits a query:
- Similarity Search: The application performs a similarity search in the vector database to find the k (defaulting to 5) most relevant document chunks to the user's query.
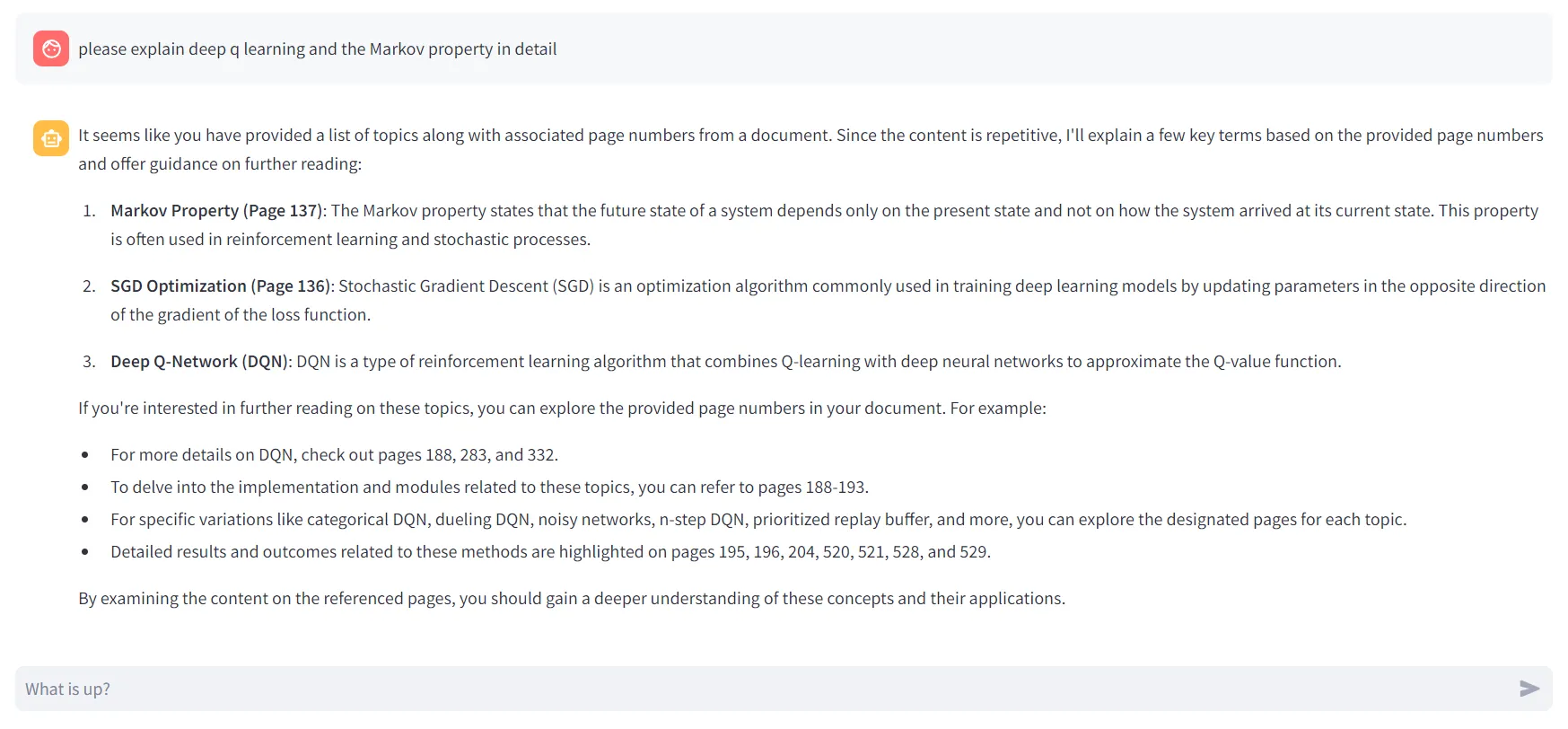
- Prompt Engineering: A PromptTemplate is used to dynamically construct a prompt for the LLM. This prompt includes the relevant document content retrieved from the vector database, guiding the LLM to provide contextually accurate answers and even specify page numbers for further reading.
- OpenAI API Integration: The processed prompt is sent to the OpenAI gpt-3.5-turbo model via the OpenAI client.
- Streamed Responses: Streamlit's st.write_stream method is utilized to display the AI-generated responses in a real-time streaming fashion, enhancing the user experience.
Implementation Details
The project's implementation details include:
- Backend: Python handles the core logic, including document loading, vector database creation, and interaction with the OpenAI API.
- NLP Pipeline: Utilizes langchain components for document loading, splitting, and integration with OpenAI's embeddings.
- Database: Chroma DB is used as the local vector store for document embeddings.
- Frontend: Streamlit provides the interactive web interface.
- API Key Management: OpenAI API key is securely loaded from a local file and set as an environment variable.
Results and Impact
This simple RAG chatbot demonstrates the effectiveness of integrating LLMs with external knowledge bases:
- Enhanced Accuracy: By retrieving relevant document chunks, the LLM can provide more accurate and context-specific answers.
- Contextual Relevance: The system can pinpoint specific information within a document, allowing for more relevant responses.
- User Experience: The Streamlit interface provides an intuitive chat-based interaction, making complex document querying accessible to users.
- Further Reading: The ability to return page numbers encourages users to delve deeper into the source document for more detailed information.
Future Enhancements
Potential future improvements for this document assistant include:
- Implementing chat history retention to allow for more probing and conversational interactions.
- Improving prompt engineering for more in-depth and nuanced explanations from the LLM.
- Expanding the types of documents supported beyond PDFs.
- Exploring different similarity search parameters (k value) and their impact on response quality.
Conclusion
This project successfully illustrates the power of Retrieval-Augmented Generation in building intelligent document assistants. By combining the strengths of LLMs with efficient information retrieval from a vector database, this tool can transform how users interact with and extract insights from complex documents, offering a dynamic and engaging experience.
Full Code
from langchain.document_loaders.pdf import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import Chroma
from langchain_core.prompts import PromptTemplate
from openai import OpenAI
import os
import streamlit as st
# Set up logging for debugging and monitoring.
import logging
logging.basicConfig(level=logging.INFO)
st.set_page_config(page_title="Simple RAG Chat Bot", page_icon=":robot:", layout="wide")
# Load the API key from the open_ai_key file
with open('open_ai_key') as f:
os.environ['OPENAI_API_KEY'] = f.read().strip()
# Use the OpenAI client for the API
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'])
# Create the vector database
def create_vector_db():
embedding_function = OpenAIEmbeddings(api_key=os.environ['OPENAI_API_KEY'])
docs = PyPDFLoader('./MY_PDF_FILE.pdf')
docs = docs.load_and_split(text_splitter=RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100))
db = Chroma.from_documents(docs, embedding_function)
return db
# Create a Prompt Template instance
prompt_template = PromptTemplate.from_template(
"You are a document assistant. Help me understand the following content: {content}. Please provide me with page numbers for further reading",
template_format='f-string'
)
st.title("Simple RAG Chat Bot")
st.subheader("Ask questions about the document './MY_PDF_FILE.pdf' and get answers from the RAG model.")
# Example usage
db = create_vector_db() # Always recreate the db for this example
if prompt := st.chat_input("What is up?"):
docs = db.similarity_search_with_relevance_scores(prompt, k=5)
concatenated_texts = ' '.join([dict(doc[0])['page_content'] for doc in docs])
formatted_prompt = prompt_template.format(content=concatenated_texts)
messages = [{
"role": "system",
"content": "You are a document assistant."
}, {
"role": "user",
"content": formatted_prompt
}]
with st.chat_message("user"):
st.markdown(prompt)
with st.chat_message("assistant"):
# Initiate streaming session
try:
stream = client.chat.completions.create(
model='gpt-3.5-turbo',
messages=messages,
stream=True
)
# Write the response to the stream
response = st.write_stream(stream)
# Append the response to the messages
messages.append({"role": "assistant", "content": response})
except Exception as e:
print(f"An error occurred: {e}")
Technologies Used
Share This Project
Interested in This Project?
Have questions or want to discuss a similar project? Feel free to reach out.
Contact Me